




Der Aufbau widerstands-fähiger Systeme mit SLOs
Der Aufbau widerstandsfähiger Systeme setzt das Vorhandensein geeigneter SLOs voraus
Beim Entwurf von Systemen ist es wichtig, sich mit möglichen Fehlern zu befassen, die während der Laufzeit auftreten können. Im Zusammenhang mit Software-Designs definieren wir einen Fehler gewöhnlich als eine Abweichung vom erwarteten Verhalten einer Software-Komponente. Ein Fehler kann zu einem oder mehreren Fehlern führen, die (abhängig von ihrer Kritikalität) eine negative Auswirkung auf unsere gesamte Softwareanwendung haben können und somit ihren regulären Betrieb beeinträchtigen können. Da sich dies nicht vollständig vermeiden lässt, müssen heutige Systeme derart konzipiert sein, dass sie mit diesen Fehlern umgehen können bzw. nicht zu solchen Ausfällen führen. Die fehlertoleranten oder robusten Systeme sind geboren.
Arten von Fehlverhalten
Wir unterscheiden zwischen drei verschiedenen Arten von Fehlern: Hardware, Software-Fehler und menschliche Fehler.
- Hardware-Fehler sind in der Regel zufällig (bis zu einem gewissen Grad) und (hoffentlich) voneinander isoliert. Das bedeutet, dass der Verlust eines Datenträgers auf Rechner A nicht mit dem Verlust von Datenträgern auf anderen Rechnern B einhergeht. Es gibt aber auch einige positive Korrelationen, insbesondere bei Hardwarekomponenten, die auf mehreren Rechnern eingesetzt werden. Um das Risiko zu mindern, ermöglichen Cloud-Anbieter die Verteilung von Anwendungen auf verschiedene Rechenzentren oder Regionen, falls es zu Hardwarefehlern kommen sollte. Es gibt auch noch andere Möglichkeiten der Hochverfügbarkeit, aber das würde den Rahmen dieses Artikels sprengen.
- Softwarefehler sind systematische Fehler innerhalb des Systems. Solche Fehler sind schwieriger vorherzusehen, und da sie über mehrere Knoten hinweg korreliert sind, verursachen sie in der Regel viel mehr Systemausfälle als unkorrelierte Hardwarefehler [1]. Auch diese Kategorie können wir trotz der Tests nicht völlig ausschließen. Andererseits gibt es Möglichkeiten, die Auswirkungen ihres Auftretens abzuschwächen, z. B. durch Prozessisolierung, Wiederholungsmechanismen, Offloading und vieles mehr.
- Auch menschliche Fehler sind nicht zu vernachlässigen. Eine Studie über große Internetdienste ergab, dass Konfigurationsfehler häufig die Hauptursache für Ausfälle sind [1]. Deshalb ist es unsere Aufgabe, Softwaresysteme so zu gestalten, dass 1) "die Fehlermöglichkeiten minimiert werden", 2) "menschliche Fehler schnell und einfach behoben werden können", 3) eine Überwachung eingerichtet wird, um proaktiv zu handeln, wenn die Fehlerraten steigen oder andere Beeinträchtigungen auftreten [1].
Wir müssen mit "Fehlern" leben
Viele Dinge können schief gehen, und wenn wir an Murphys Gesetz glauben: Alles, was schief gehen kann, wird auch schief gehen. [2], dann sollten wir versuchen, die Auswirkungen so weit wie möglich zu reduzieren. Das ist keine einfache Aufgabe, vor allem wenn man sich die zunehmende Größe und Komplexität der heutigen Systeme ansieht. In der Vergangenheit gab es mehrere Ausfälle, die enorme Auswirkungen hatten [3][4]. Dennoch ist es unsere Aufgabe, aus unseren Fehlern und den gesammelten Erfahrungen in diesem Bereich zu lernen. Aber wir haben nicht die Zeit, nur für uns selbst zu lernen:
Learn from the mistakes of others. You can't live long enough to make them all yourself" - Eleanor Roosevelt
Die grundlegende Frage, die sich in Ihrem Kopf stellen sollte, lautet: Wie können wir ein System entwerfen, das (bis zu einem gewissen Grad) robust gegenüber Fehlern ist? Natürlich kann ich Ihnen einige Muster und Best Practices vorschlagen (ich werde versuchen, dies in einigen kommenden technischen Beiträgen zu tun 👹), aber dies ist nicht wirklich zielorientiert. Zunächst müssen wir klare Ziele definieren, die erreicht werden können und wirklich "messbar" sind, ähnlich wie bei Objectives and Key Results (OKR) [5].
Definition eines Zielzustands
Wir verwenden ein Konzept mit der Bezeichnung Service Level Objectives (SLO). Ein Konzept, das häufig mit der Schaffung einer Terminologie einhergeht, die Sie im Folgenden finden:
- Service Level Indicators (SLIs) sind Metriken, die Einblicke in Ihr laufendes Softwaresystem geben.
- Service Level Objectives (SLOs) basieren auf SLIs und stellen das Ziel dar, das Sie mit Ihrem Softwaresystem erreichen wollen. Im Folgenden nennen wir dies unsere Service-Baseline.
- Service Level Agreements (SLAs) sind Verträge zwischen einem Service Provider und einem oder mehreren Service Consumern. In der Regel enthalten sie eine Sammlung von SLOs, die umreißen, was Servicekunden von Ihnen erwarten können.
- Fehlerbudgets stellen eine akzeptable Spanne zwischen Ihren aktuellen SLIs und den definierten SLOs dar.
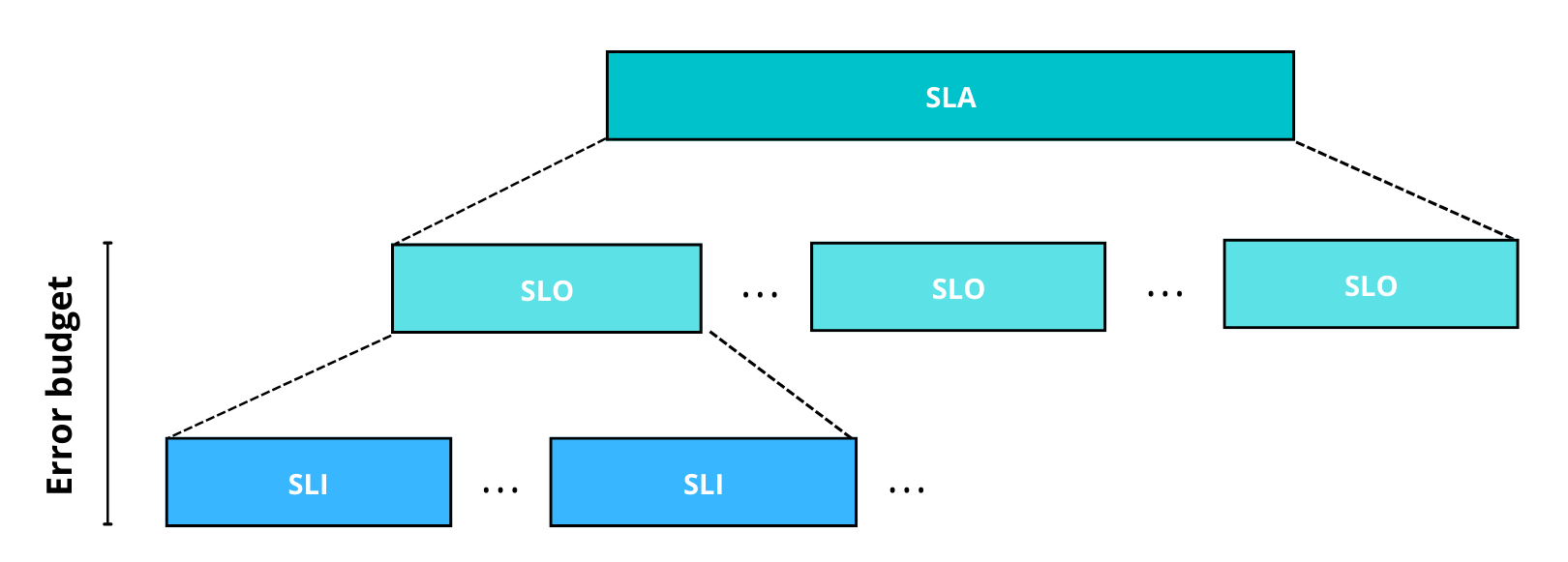
Ableiten von Service-Level-Ziele (SLOs)
SLOs ermöglichen es uns, Entscheidungen auf der Grundlage von SLIs (realen Daten) zu treffen, und geben uns die Möglichkeit, Prioritäten zu setzen. Dies ist besonders wichtig, da eine verpasste Basislinie negative Auswirkungen auf unsere Dienstnutzer haben können.
Die Auswahl eines geeigneten SLO für Ihren Dienst ist keine leichte Aufgabe [6]. Sie müssen hier zwischen verschiedenen Arten von Diensten unterscheiden (z. B. benutzerorientierte Dienste, Arbeitsabläufe oder Systeme mit künstlicher Intelligenz (KI)), was die Komplexität zusätzlich noch erhöht. Um zu nützlichen SLOs zu kommen, ist eine gute Herangehensweise, diese Herausforderung mit einem Bottom-up-Ansatz anzugehen. Das bedeutet: Denken Sie nicht darüber nach, was "gut" für die Nutzer sind, sondern stattdessen, was leicht zu messen ist. Wenn Sie dies mit dem Wissen über Ihren angebotenen Dienst und dessen Auswirkungen auf Ihr Unternehmen kombinieren, können Sie nützliche SLOs ableiten.
Beispiel:
Es ist einfach, die Anforderungszeit eines Dienstaufrufs (Request Time) zu messen. Auf dieser Grundlage definieren wir die folgenden SLOs, da wir uns der Tatsache bewusst sind, dass langsame Anfragen einen negativen Einfluss auf die Benutzererfahrung haben. Eine schlechte Benutzererfahrung resultiert aus der Wartezeit für eine Interaktion, die wiederum zu einer geringeren Produktivität führt. Für die meisten Menschen (wie z. B. mich) ist das nicht wirklich zufriedenstellend, weshalb derartige Personen zwangsläufig nach Alternativen suchen werden.
- 95% unserer HTTP GET Endpunktaufrufe werden in weniger als 300ms verarbeitet
- 90 % unserer HTTP-GET-Endpunktaufrufe werden in weniger als 100 ms verarbeitet
- 90 % unserer HTTP-GET-Endpunkte mit Aufrufen werden in weniger als 100 ms verarbeitet
- 95% unserer HTTP PUT/POST Endpunktaufrufe werden in weniger als 1s verarbeitet
- 90 % unserer HTTP PUT/POST-Endpunkte mit Aufrufen mit einer Nutzlast von weniger als 500 KB werden in weniger als 100 ms verarbeitet.
Eine Empfehlung aus unseren bisherigen Erfahrungen im Umgang mit SLOs: Bestehen Sie nicht blind auf der Erfüllung aller definierten SLOs, da dies die Innovation bremsen könnte. Beziehen Sie sich stattdessen auf Ihr definiertes Fehlerbudget (so erhalten Sie einen objektiven Überblick über Ihre aktuelle Servicequalität).
Verfolgung Ihrer Service-Level-Ziele
Die Verfolgung Ihrer SLOs ist ein fortlaufender Prozess und sollte nicht manuell erfolgen (unabhängig von der Tatsache, dass man sich die Mühe sparen will: “eliminating the toil”). Verwenden Sie stattdessen ein spezielles System für die Erfassung der benötigten SLIs und vergleichen und visualisieren Sie die Ergebnisse mit Ihren definierten SLOs. Das Fehlerbudget gibt eine Ober- bzw. Untergrenze vor, ab der ein SLO als nicht erfüllt gilt. Ein weiterer Vorteil eines solchen Ansatzes ist die daraus resultierende Transparenz für jedes Projektmitglied.
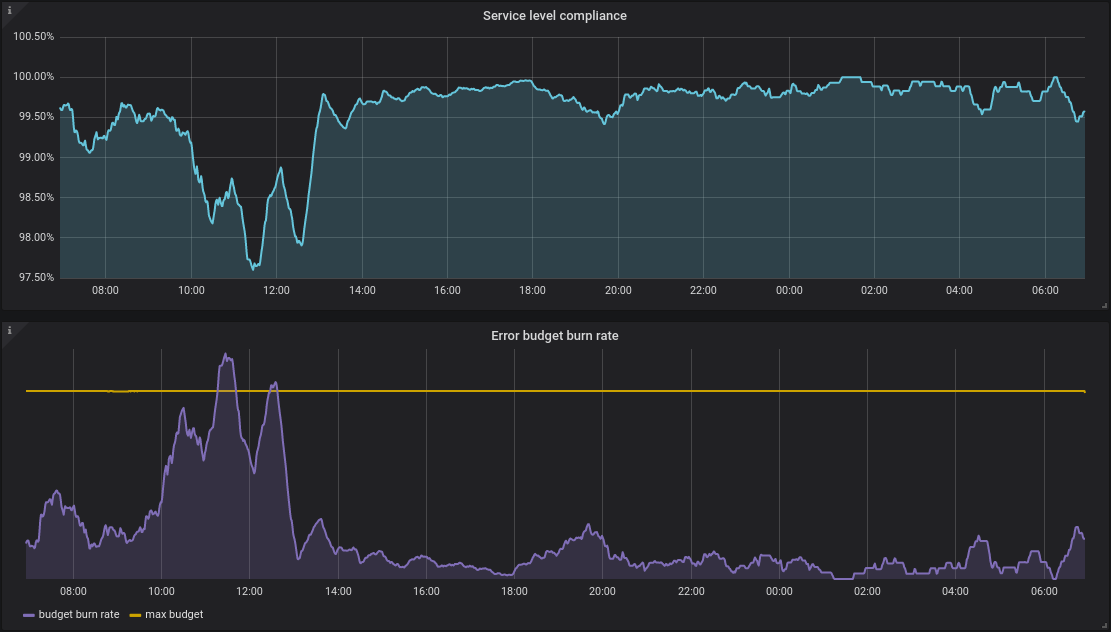
(vereinfachte Sichtweise: [https://grafana.com/grafana/dashboards/8793-service-level-sli-slo/](https://grafana. com/grafana/dashboards/8793-service-level-sli-slo/)) [7]
Ergreifen von Maßnahmen
Der letzte Teil stellt die Ableitung von Maßnahmen auf der Grundlage der gewonnenen Erkenntnisse über Ihre Dienste dar. Eine Maßnahme könnte der Fokus auf die Korrektur von nicht erfüllten SLOs hinsichtlich ihres Fehlerbudgets sein oder ein hybrider Ansatz durch die Gewährung neuer Servicefunktionen unter Berücksichtigung der Verbesserung unserer Servicequalität. Letztendlich liegt es in Ihrer Verantwortung, welche Maßnahmen ergriffen werden. Die SLOs liefern uns lediglich eine objektive Diskussionsgrundlage. Und im Laufe der Zeit können weitere SLOs hinzugefügt werden, die die notwendige und erwartete Qualität besser repräsentieren - fangen Sie also nicht mit zu vielen an (wie immer gilt: einfach halten und mit der Zeit erweitern).
Ich hoffe, ich konnte Ihnen einen guten Einblick geben, wie SLOs und das Konzept der Fehlerbudgets die nötige Orientierung beim Aufbau belastbarer Systeme bieten und gleichzeitig Innovation und Zuverlässigkeit im Gleichgewicht halten können. Am Anfang ist dies sicherlich keine leichte Aufgabe, aber die Konzepte werden mit der Zeit ihr vollen Potenzial entfalten. Cheers
PG
[1] Kleppmann, Martin. Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems
[2] Lloyd Mallan, in Men, Rockets and Space Rats (1955), possibly the earliest printed use of Murphy's name in connection with the law.
[4] https://blog.cloudflare.com/october-2021-facebook-outage/
[5] John Doerr, Measure What Matters: OKRs: The Simple Idea that Drives 10x Growth
[6] Betsy Beyer, Niall Richard Murphy, Jennifer Petoff, Chris Jones: Site Reliability Engineering: How Google Runs Productive Systems
[7] Grafana: The open observability platform | Grafana Labs https://grafana.com/